Train Variational Quantum Circuits by using f-evovaq and Qiskit
1) Training a Variational Quantum Classifier through a Memetic Algorithm
Importing modules
[3]:
import numpy as np
import cupy as cp
from functools import partial
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss, accuracy_score
from sklearn.preprocessing import MinMaxScaler
from qiskit.circuit.library import TwoLocal
from qiskit_aer.quantum_info import AerStatevector
from qiskit import QuantumCircuit
from qiskit.circuit import ParameterVector
from fevovaq.problem import Problem
from fevovaq.GeneticAlgorithm import GA
from fevovaq.HillClimbing import HC
from fevovaq.MemeticAlgorithm import MA
from fevovaq.tools.operators import sel_tournament, cx_uniform, mut_gaussian, sel_best
Uploading the classical data
[4]:
iris = load_iris()
# For the sake of simplicity, we consider all the four features but only two classes
iris_data = iris.data[:100, :4]
iris_target = iris.target[:100] # 0 or 1
# Split into train and test subsets
train_data, test_data, train_labels, test_labels = train_test_split(iris_data, iris_target, test_size=0.2,
random_state=42)
# Pre-processing
scaler = MinMaxScaler(feature_range=(-np.pi, np.pi))
scaler.fit(train_data)
train_data = scaler.transform(train_data)
test_data = scaler.transform(test_data)
Building the Variational Quantum Classifier
[5]:
def AngleEncoding(n_qubits, rotation="ry"):
features = ParameterVector('f', n_qubits)
qc = QuantumCircuit(n_qubits, 1)
for i in range(n_qubits):
if rotation == "rx":
qc.rx(features[i], i)
elif rotation == "ry":
qc.ry(features[i], i)
elif rotation == "rz":
qc.rz(features[i], i)
else:
raise ValueError("rotation must be 'rx', 'ry', or 'rz'")
return qc
[6]:
# Encode classical data in a quantum system through a FeatureMap
reps = 5
n_qubits = train_data.shape[1] # Number of qubits
feature_map = AngleEncoding(n_qubits)
# Define an Ansatz to be trained
ansatz = TwoLocal(num_qubits=n_qubits, entanglement='reverse_linear', rotation_blocks='u3', reps=reps,
entanglement_blocks='cx', skip_final_rotation_layer=True)
# Put together our quantum classifier
classifier = feature_map.compose(ansatz)
classifier.decompose().draw()
[6]:
┌─────────────┐ ┌────────────────────┐ »
q_0: ┤ R(f[0],π/2) ├─┤ U3(θ[2],θ[1],θ[0]) ├───────────────────────────────»
├─────────────┤ ├────────────────────┤ »
q_1: ┤ R(f[1],π/2) ├─┤ U3(θ[5],θ[4],θ[3]) ├──────────────────■────────────»
├─────────────┤ ├────────────────────┤ ┌─┴─┐ »
q_2: ┤ R(f[2],π/2) ├─┤ U3(θ[8],θ[7],θ[6]) ├───■────────────┤ X ├──────────»
├─────────────┤┌┴────────────────────┴┐┌─┴─┐┌─────────┴───┴─────────┐»
q_3: ┤ R(f[3],π/2) ├┤ U3(θ[11],θ[10],θ[9]) ├┤ X ├┤ U3(θ[23],θ[22],θ[21]) ├»
└─────────────┘└──────────────────────┘└───┘└───────────────────────┘»
c: 1/═════════════════════════════════════════════════════════════════════»
»
« ┌───────────────────────┐»
«q_0: ────────────■────────────┤ U3(θ[14],θ[13],θ[12]) ├»
« ┌─┴─┐ ├───────────────────────┤»
«q_1: ──────────┤ X ├──────────┤ U3(θ[17],θ[16],θ[15]) ├»
« ┌─────────┴───┴─────────┐└───────────────────────┘»
«q_2: ┤ U3(θ[20],θ[19],θ[18]) ├────────────■────────────»
« └───────────────────────┘ ┌─┴─┐ »
«q_3: ───────────────────────────────────┤ X ├──────────»
« └───┘ »
«c: 1/══════════════════════════════════════════════════»
« »
« »
«q_0: ─────────────────────────────────────■────────────»
« ┌─┴─┐ »
«q_1: ────────────■──────────────────────┤ X ├──────────»
« ┌─┴─┐ ┌─────────┴───┴─────────┐»
«q_2: ──────────┤ X ├──────────┤ U3(θ[32],θ[31],θ[30]) ├»
« ┌─────────┴───┴─────────┐└───────────────────────┘»
«q_3: ┤ U3(θ[35],θ[34],θ[33]) ├─────────────────────────»
« └───────────────────────┘ »
«c: 1/══════════════════════════════════════════════════»
« »
« ┌───────────────────────┐ »
«q_0: ┤ U3(θ[26],θ[25],θ[24]) ├─────────────────────────»
« ├───────────────────────┤ »
«q_1: ┤ U3(θ[29],θ[28],θ[27]) ├────────────■────────────»
« └───────────────────────┘ ┌─┴─┐ »
«q_2: ────────────■──────────────────────┤ X ├──────────»
« ┌─┴─┐ ┌─────────┴───┴─────────┐»
«q_3: ──────────┤ X ├──────────┤ U3(θ[47],θ[46],θ[45]) ├»
« └───┘ └───────────────────────┘»
«c: 1/══════════════════════════════════════════════════»
« »
« ┌───────────────────────┐»
«q_0: ────────────■────────────┤ U3(θ[38],θ[37],θ[36]) ├»
« ┌─┴─┐ ├───────────────────────┤»
«q_1: ──────────┤ X ├──────────┤ U3(θ[41],θ[40],θ[39]) ├»
« ┌─────────┴───┴─────────┐└───────────────────────┘»
«q_2: ┤ U3(θ[44],θ[43],θ[42]) ├────────────■────────────»
« └───────────────────────┘ ┌─┴─┐ »
«q_3: ───────────────────────────────────┤ X ├──────────»
« └───┘ »
«c: 1/══════════════════════════════════════════════════»
« »
« »
«q_0: ─────────────────────────────────────■────────────»
« ┌─┴─┐ »
«q_1: ────────────■──────────────────────┤ X ├──────────»
« ┌─┴─┐ ┌─────────┴───┴─────────┐»
«q_2: ──────────┤ X ├──────────┤ U3(θ[56],θ[55],θ[54]) ├»
« ┌─────────┴───┴─────────┐└───────────────────────┘»
«q_3: ┤ U3(θ[59],θ[58],θ[57]) ├─────────────────────────»
« └───────────────────────┘ »
«c: 1/══════════════════════════════════════════════════»
« »
« ┌───────────────────────┐
«q_0: ┤ U3(θ[50],θ[49],θ[48]) ├───────■──
« ├───────────────────────┤ ┌─┴─┐
«q_1: ┤ U3(θ[53],θ[52],θ[51]) ├──■──┤ X ├
« └───────────────────────┘┌─┴─┐└───┘
«q_2: ────────────■────────────┤ X ├─────
« ┌─┴─┐ └───┘
«q_3: ──────────┤ X ├────────────────────
« └───┘
«c: 1/═══════════════════════════════════
« [7]:
def get_label(params, classifier, test_data, problem):
xp = problem.xp
if xp.__name__ == 'cupy':
params = xp.asnumpy(params)
bound_circuit = classifier.assign_parameters(np.concatenate((test_data, params)))
sv = AerStatevector(bound_circuit , device='GPU')
probs = sv.probabilities([0])
return 1 if probs[1] > 0.5 else 0
Defining the cost function to be minimized
[8]:
def cost_function(params, classifier, train_data, train_labels):
n_samples = train_data.shape[0]
# Convert CuPy array as NumPy because Qiskit doesn't support GPU-based arrays
params = cp.asnumpy(params)
params_reshaped = np.tile(params, (n_samples, 1))
all_params_np = np.concatenate((train_data, params_reshaped), axis=1)
preds = np.zeros(n_samples)
for i, params_inst in enumerate(all_params_np):
bound_circuits = classifier.assign_parameters(params_inst)
sv = AerStatevector(bound_circuits , device='GPU')
probs = sv.probabilities([0])
preds[i] = probs[1]
return log_loss(train_labels, preds)
Setting up the problem
[9]:
cost_func = partial(cost_function, classifier=classifier, train_data=train_data, train_labels=train_labels)
problem = Problem(n_params=ansatz.num_parameters, param_bounds=ansatz.parameter_bounds, init_range=(-cp.pi, cp.pi),
obj_function=cost_func, backend='gpu', vectorized=False)
Defining a Memetic Algorithm
[10]:
# Define the global search method
global_search = GA(selection=sel_tournament, crossover=cx_uniform, mutation=mut_gaussian, sigma=0.2, mut_indpb=0.15,
cxpb=0.9, tournsize=5)
# Create a neighbour of a possible solution
def get_neighbour(problem, current_solution):
xp = problem.xp
neighbour = current_solution.copy()
index = xp.random.randint(0, problem.n_params, size=1)
neighbour[index] = xp.random.uniform(-xp.pi, xp.pi, size=1)
return neighbour
# Define the local search method
local_search = HC(generate_neighbour=get_neighbour)
# Compose the global and local search method for a Memetic Algorithm
optimizer = MA(global_search=global_search.evolve_population, sel_for_refinement=sel_best, local_search=local_search.stochastic_var, frequency=0.1, intensity=10)
Training our VQC
[11]:
res = optimizer.optimize(problem, pop_size=10, max_gen=10, verbose=True, seed=42)
res
Generations: 0%| | 0/10 [00:00<?, ?gen/s]
********** Execution #1 **********
gen nfev min max mean std
----- ------ -------- -------- -------- --------
0 10 0.448778 0.885639 0.711605 0.123813
Generations: 10%|███ | 1/10 [00:02<00:19, 2.21s/gen]
1 20 0.448778 0.892065 0.740525 0.143335
Generations: 20%|██████ | 2/10 [00:04<00:16, 2.07s/gen]
2 20 0.448778 0.884432 0.730048 0.124827
Generations: 30%|█████████ | 3/10 [00:06<00:14, 2.04s/gen]
3 20 0.448778 0.798723 0.699879 0.0958409
Generations: 40%|████████████ | 4/10 [00:08<00:12, 2.02s/gen]
4 20 0.448778 0.895857 0.661903 0.126814
Generations: 50%|███████████████ | 5/10 [00:10<00:10, 2.02s/gen]
5 20 0.448778 0.940913 0.758427 0.125662
Generations: 60%|██████████████████ | 6/10 [00:12<00:08, 2.01s/gen]
6 20 0.448778 0.821422 0.644119 0.128682
Generations: 70%|█████████████████████ | 7/10 [00:14<00:06, 2.03s/gen]
7 20 0.448778 0.717158 0.55156 0.0767636
Generations: 80%|████████████████████████ | 8/10 [00:16<00:04, 2.02s/gen]
8 20 0.43301 0.521759 0.476904 0.0321787
Generations: 90%|███████████████████████████ | 9/10 [00:18<00:02, 2.02s/gen]
9 20 0.383075 0.511485 0.456047 0.033578
Generations: 100%|█████████████████████████████| 10/10 [00:20<00:00, 2.03s/gen]
10 20 0.374914 0.524138 0.441109 0.0447009
[11]:
fun: array(0.37491382)
gen: 10
log: {'gen': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'nfev': [10, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20], 'min': [array(0.44877768), array(0.44877768), array(0.44877768), array(0.44877768), array(0.44877768), array(0.44877768), array(0.44877768), array(0.44877768), array(0.43300969), array(0.38307533), array(0.37491382)], 'max': [array(0.88563912), array(0.89206535), array(0.88443177), array(0.79872295), array(0.89585688), array(0.94091294), array(0.82142174), array(0.7171575), array(0.5217589), array(0.51148517), array(0.52413836)], 'mean': [array(0.7116047), array(0.74052451), array(0.73004844), array(0.69987924), array(0.66190269), array(0.75842726), array(0.64411938), array(0.55156003), array(0.47690374), array(0.45604707), array(0.44110942)], 'std': [array(0.12381267), array(0.14333453), array(0.12482709), array(0.09584085), array(0.12681402), array(0.12566232), array(0.12868223), array(0.07676358), array(0.03217866), array(0.03357805), array(0.04470089)]}
nfev: 210
x: array([ 2.66756446, 1.88347094, -2.67819543, -0.86081502, 0.07447794,
-1.69281126, 0.04354438, 1.13787173, 0.87256201, 1.03553065,
3.20766494, 0.54151417, -0.90258819, -2.6057128 , 1.68382911,
-2.19062974, -2.59953377, 0.23649704, 2.68102339, -1.58245806,
0.29607596, 0.24048514, 2.73712106, -0.11428715, 0.62380583,
-2.59104795, 0.96932751, 0.48425987, -3.10073629, -0.08926363,
-1.35770848, 1.13112516, 0.32676846, -0.04495667, -1.88844294,
1.42374158, 1.09768481, -0.2076989 , -0.59348811, 1.46291578,
2.40236227, -2.64686819, 2.58232254, -2.66135108, 0.9215397 ,
2.33880593, 2.6188431 , 3.16970774, 2.26524258, -1.72029359,
1.8109968 , -1.40636385, 1.91533376, -2.53913955, -2.56059053,
-3.12272377, -2.05883532, -1.04306676, 2.43778751, -0.30886724])
Testing the optimal solution found
[12]:
test_preds = [get_label(res.x, classifier, feats, problem) for feats in test_data]
test_accuracy = accuracy_score(test_labels, test_preds)
print("Accuracy on the test subset:", test_accuracy)
Accuracy on the test subset: 0.95
2) QAOA trained by a CHC algorithm to solve MaxCut problem
Importing modules
[13]:
import networkx as nx
import numpy as np
from functools import partial
import cupy as cp
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
from qiskit_aer import AerSimulator
from qiskit.visualization import plot_histogram
from qiskit_optimization.applications import Maxcut
from qiskit.circuit.library import QAOAAnsatz
from fevovaq.problem import Problem
from fevovaq.CHCAlgorithm import CHC
from fevovaq.tools.operators import cx_blx_alpha
from fevovaq.tools.distances import fitness_l1
Defining the graph
[14]:
num_nodes = 5
edges = [(0, 1), (0, 2), (0, 3), (0, 4)]
G = nx.Graph()
G.add_nodes_from(range(num_nodes))
G.add_edges_from(edges)
nx.draw(G, with_labels=True)
Mapping the MaxCut problem in a QAOA circuit ansatz
1 - Trasforming the MaxCut instance in a quadratic problem
[15]:
maxcut_prob = Maxcut(G)
maxcut_qp = maxcut_prob.to_quadratic_program()
print(maxcut_qp.prettyprint())
Problem name: Max-cut
Maximize
-2*x_0*x_1 - 2*x_0*x_2 - 2*x_0*x_3 - 2*x_0*x_4 + 4*x_0 + x_1 + x_2 + x_3 + x_4
Subject to
No constraints
Binary variables (5)
x_0 x_1 x_2 x_3 x_4
2 - Defining the Hamiltonian by mapping the QUBO problem in an Ising Model
[16]:
# MaxCut problem to Hamiltonian operator
hamiltonian, offset = maxcut_qp.to_ising()
3 - Building the QAOA circuit based on the MaxCut instance
[17]:
# QAOA ansatz circuit
qaoa_circuit = QAOAAnsatz(hamiltonian, reps=2)
qaoa_circuit.measure_all()
qaoa_circuit.decompose(reps=3).draw()
[17]:
┌─────────────┐ »
q_0: ┤ U3(π/2,0,π) ├──■────────────────────■─────────────────────■──»
├─────────────┤┌─┴─┐┌──────────────┐┌─┴─┐┌───────────────┐ │ »
q_1: ┤ U3(π/2,0,π) ├┤ X ├┤ Rz(1.0*γ[0]) ├┤ X ├┤ R(2.0*β[0],0) ├──┼──»
├─────────────┤└───┘└──────────────┘└───┘└───────────────┘┌─┴─┐»
q_2: ┤ U3(π/2,0,π) ├───────────────────────────────────────────┤ X ├»
├─────────────┤ └───┘»
q_3: ┤ U3(π/2,0,π) ├────────────────────────────────────────────────»
├─────────────┤ »
q_4: ┤ U3(π/2,0,π) ├────────────────────────────────────────────────»
└─────────────┘ »
meas: 5/═══════════════════════════════════════════════════════════════»
»
« »
« q_0: ──────────────────■─────────────────────■────────────────────■──»
« │ │ │ »
« q_1: ──────────────────┼─────────────────────┼────────────────────┼──»
« ┌──────────────┐┌─┴─┐┌───────────────┐ │ │ »
« q_2: ┤ Rz(1.0*γ[0]) ├┤ X ├┤ R(2.0*β[0],0) ├──┼────────────────────┼──»
« └──────────────┘└───┘└───────────────┘┌─┴─┐┌──────────────┐┌─┴─┐»
« q_3: ──────────────────────────────────────┤ X ├┤ Rz(1.0*γ[0]) ├┤ X ├»
« └───┘└──────────────┘└───┘»
« q_4: ────────────────────────────────────────────────────────────────»
« »
«meas: 5/════════════════════════════════════════════════════════════════»
« »
« ┌───────────────┐ »
« q_0: ───────────────────■────────────────────■──┤ R(2.0*β[0],0) ├──■──»
« │ │ └───────────────┘┌─┴─┐»
« q_1: ───────────────────┼────────────────────┼───────────────────┤ X ├»
« │ │ └───┘»
« q_2: ───────────────────┼────────────────────┼────────────────────────»
« ┌───────────────┐ │ │ »
« q_3: ┤ R(2.0*β[0],0) ├──┼────────────────────┼────────────────────────»
« └───────────────┘┌─┴─┐┌──────────────┐┌─┴─┐┌───────────────┐ »
« q_4: ─────────────────┤ X ├┤ Rz(1.0*γ[0]) ├┤ X ├┤ R(2.0*β[0],0) ├─────»
« └───┘└──────────────┘└───┘└───────────────┘ »
«meas: 5/═════════════════════════════════════════════════════════════════»
« »
« »
« q_0: ──────────────────■────■─────────────────────■────■───────────────────»
« ┌──────────────┐┌─┴─┐ │ ┌───────────────┐ │ │ »
« q_1: ┤ Rz(1.0*γ[1]) ├┤ X ├──┼──┤ R(2.0*β[1],0) ├──┼────┼───────────────────»
« └──────────────┘└───┘┌─┴─┐└┬──────────────┤┌─┴─┐ │ ┌───────────────┐»
« q_2: ─────────────────────┤ X ├─┤ Rz(1.0*γ[1]) ├┤ X ├──┼──┤ R(2.0*β[1],0) ├»
« └───┘ └──────────────┘└───┘┌─┴─┐└┬──────────────┤»
« q_3: ────────────────────────────────────────────────┤ X ├─┤ Rz(1.0*γ[1]) ├»
« └───┘ └──────────────┘»
« q_4: ──────────────────────────────────────────────────────────────────────»
« »
«meas: 5/══════════════════════════════════════════════════════════════════════»
« »
« ┌───────────────┐ ░ »
« q_0: ──■─────────────────────■────────────────────■──┤ R(2.0*β[1],0) ├─░─»
« │ │ │ └───────────────┘ ░ »
« q_1: ──┼─────────────────────┼────────────────────┼────────────────────░─»
« │ │ │ ░ »
« q_2: ──┼─────────────────────┼────────────────────┼────────────────────░─»
« ┌─┴─┐┌───────────────┐ │ │ ░ »
« q_3: ┤ X ├┤ R(2.0*β[1],0) ├──┼────────────────────┼────────────────────░─»
« └───┘└───────────────┘┌─┴─┐┌──────────────┐┌─┴─┐┌───────────────┐ ░ »
« q_4: ──────────────────────┤ X ├┤ Rz(1.0*γ[1]) ├┤ X ├┤ R(2.0*β[1],0) ├─░─»
« └───┘└──────────────┘└───┘└───────────────┘ ░ »
«meas: 5/════════════════════════════════════════════════════════════════════»
« »
« ┌─┐
« q_0: ┤M├────────────
« └╥┘┌─┐
« q_1: ─╫─┤M├─────────
« ║ └╥┘┌─┐
« q_2: ─╫──╫─┤M├──────
« ║ ║ └╥┘┌─┐
« q_3: ─╫──╫──╫─┤M├───
« ║ ║ ║ └╥┘┌─┐
« q_4: ─╫──╫──╫──╫─┤M├
« ║ ║ ║ ║ └╥┘
«meas: 5/═╩══╩══╩══╩══╩═
« 0 1 2 3 4 Setting up the Estimator and Sampler
[18]:
quantum_backend = AerSimulator()
# Set the transpiler
pm = generate_preset_pass_manager(backend=quantum_backend, optimization_level=0)
# Set the Estimator and Sampler
estimator = Estimator(quantum_backend)
sampler = Sampler(quantum_backend)
Defining the cost function to be minimized
[19]:
def cost_function(params, circuit, hamiltonian, estimator, pm):
# Transpile the circuit to ISA circuit
params = cp.asnumpy(params)
circuit_isa = pm.run(circuit)
hamiltonian_isa = hamiltonian.apply_layout(circuit_isa.layout)
pub = (circuit_isa, [hamiltonian_isa], [params])
# Submit the circuit to estimator and get the result
result = estimator.run(pubs=[pub]).result()
# Extract the expectation value
cost = result[0].data.evs[0]
return cost
Setting up the problem
[20]:
cost_func = partial(cost_function, circuit=qaoa_circuit, hamiltonian=hamiltonian, estimator=estimator, pm=pm)
problem = Problem(n_params=qaoa_circuit.num_parameters, param_bounds=qaoa_circuit.parameter_bounds,
init_range=(0, 2* cp.pi), obj_function=cost_func, backend='gpu', vectorized=False)
Defining the CHC algorithm
[21]:
optimizer = CHC(crossover=cx_blx_alpha, distance=fitness_l1)
Training the QAOA circuit
[22]:
res = optimizer.optimize(problem, 10, max_nfev=100, seed=42)
res
Fitness Evaluations: 18%|███▏ | 18/100 [00:00<00:00, 130.30nfev/s]
********** Execution #1 **********
gen nfev min max mean std
----- ------ -------- -------- --------- --------
0 10 -1.01929 0.398193 -0.397485 0.404733
1 2 -1.01929 0.398193 -0.397485 0.404733
2 6 -1.01929 -0.180908 -0.513013 0.278676
Fitness Evaluations: 32%|██████ | 32/100 [00:00<00:00, 91.84nfev/s]
3 6 -1.01929 -0.374512 -0.738574 0.230201
4 4 -1.01929 -0.499756 -0.789917 0.198326
5 2 -1.01929 -0.559326 -0.810059 0.176906
6 2 -1.01929 -0.559326 -0.810059 0.176906
7 4 -1.01929 -0.5625 -0.850708 0.160571
Fitness Evaluations: 56%|██████████▋ | 56/100 [00:00<00:00, 79.03nfev/s]
8 6 -1.01929 -0.61084 -0.878979 0.129153
9 4 -1.01929 -0.660889 -0.883984 0.119255
10 2 -1.01929 -0.660889 -0.883984 0.119255
11 8 -1.01929 -0.701172 -0.894385 0.102736
Fitness Evaluations: 79%|███████████████ | 79/100 [00:00<00:00, 76.97nfev/s]
12 10 -1.01929 -0.841797 -0.938281 0.0651745
13 13 -1.01929 0.190186 -0.485571 0.35726
Fitness Evaluations: 99%|██████████████████▊| 99/100 [00:01<00:00, 77.06nfev/s]
14 8 -1.01929 -0.227051 -0.597925 0.29594
15 0 -1.01929 -0.227051 -0.597925 0.29594
16 6 -1.40649 -0.386475 -0.795483 0.271876
17 6 -1.5061 -0.566162 -0.907983 0.307864
Fitness Evaluations: 105nfev [00:01, 80.39nfev/s]
18 6 -1.5061 -0.566162 -0.907983 0.307864
[22]:
fun: array(-1.50610352)
gen: 19
log: {'gen': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18], 'nfev': [10, 2, 6, 6, 4, 2, 2, 4, 6, 4, 2, 8, 10, 13, 8, 0, 6, 6, 6], 'min': [array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.01928711), array(-1.40649414), array(-1.50610352), array(-1.50610352)], 'max': [array(0.39819336), array(0.39819336), array(-0.1809082), array(-0.37451172), array(-0.49975586), array(-0.55932617), array(-0.55932617), array(-0.5625), array(-0.61083984), array(-0.66088867), array(-0.66088867), array(-0.70117188), array(-0.84179688), array(0.19018555), array(-0.22705078), array(-0.22705078), array(-0.38647461), array(-0.56616211), array(-0.56616211)], 'mean': [array(-0.39748535), array(-0.39748535), array(-0.5130127), array(-0.73857422), array(-0.78991699), array(-0.81005859), array(-0.81005859), array(-0.85070801), array(-0.87897949), array(-0.88398438), array(-0.88398438), array(-0.89438477), array(-0.93828125), array(-0.48557129), array(-0.5979248), array(-0.5979248), array(-0.7954834), array(-0.9079834), array(-0.9079834)], 'std': [array(0.40473292), array(0.40473292), array(0.27867585), array(0.23020122), array(0.19832642), array(0.17690649), array(0.17690649), array(0.16057095), array(0.12915256), array(0.11925523), array(0.11925523), array(0.10273635), array(0.06517446), array(0.35725997), array(0.29594042), array(0.29594042), array(0.27187597), array(0.30786416), array(0.30786416)]}
nfev: 105
x: array([5.11467318, 4.10246673, 4.38589537, 3.07366605])
Testing the optimal angles found
[25]:
# Transpile the circuit to ISA circuit
params = cp.asnumpy(res.x)
qaoa_isa = pm.run(qaoa_circuit)
pub = (qaoa_isa, params)
# Submit the circuit to sampler
job = sampler.run([pub])
# Collect data to get the counts
pub_results = job.result()[0]
counts = pub_results.data.meas.get_counts()
plot_histogram(counts, title='Distribution of the final counts')
[25]:
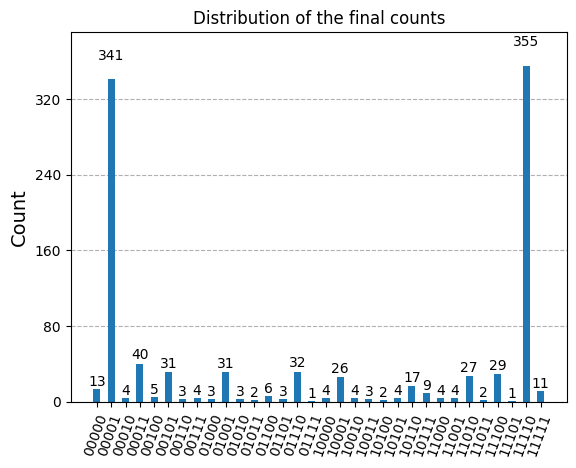
[26]:
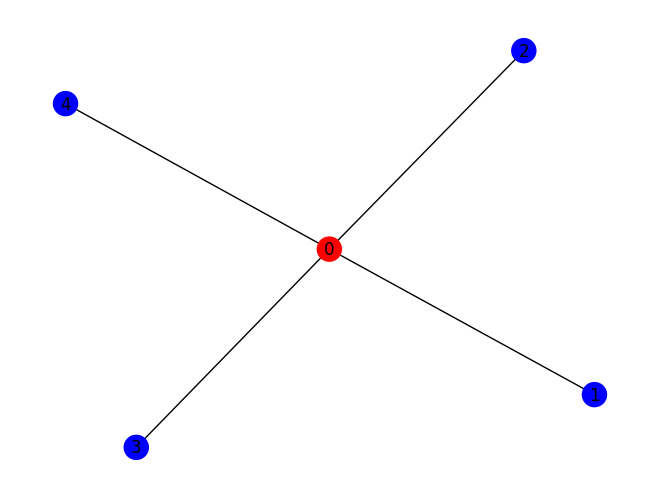
bitstring = maxcut_prob.sample_most_likely(counts)
print('Optimal solution: ', bitstring)
Optimal solution: [0 1 1 1 1]
[27]:
maxcut_prob.draw(bitstring)
Train Variational Quantum Classifiers by using f-evovaq and PennyLane
[2]:
import numpy as np
import cupy as cp
from functools import partial
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss, accuracy_score
from sklearn.preprocessing import MinMaxScaler
from fevovaq.problem import Problem
from fevovaq.GeneticAlgorithm import GA
from fevovaq.tools.operators import sel_tournament, cx_uniform, mut_gaussian
import pennylane as qml
[13]:
def setup_pennylane_circuit(n_qubits, reps):
dev = qml.device("default.qubit", wires=n_qubits)
@qml.qnode(dev, interface=None, diff_method=None)
def circuit(inputs, weights):
weights = cp.asnumpy(weights)
qml.AngleEmbedding(inputs, wires=range(n_qubits), rotation='Y')
weights = weights.reshape(reps, n_qubits, 3)
qml.StronglyEntanglingLayers(weights, wires=range(n_qubits))
return qml.probs(wires=0)
return circuit
def cost_function(params, qnode, train_data, train_labels):
"""
Compute the probability of being in state |1> and use it to compute log_loss.
"""
probs = qnode(train_data, params)
return log_loss(train_labels, probs[:, 1])
def get_label(params, qnode, test_data):
"Predict label for each test istance"
probs = qnode(test_data, params)
return 1 if probs[1] > 0.5 else 0
[14]:
data = load_iris()
features = data.data[:100, :]
target = data.target[:100] # 0 or 1
train_data, test_data, train_labels, test_labels = train_test_split(features, target, test_size=0.3,
random_state=123, stratify=target)
# Pre-processing
scaler = MinMaxScaler(feature_range=(-np.pi, np.pi))
scaler.fit(train_data)
train_data = scaler.transform(train_data)
test_data = scaler.transform(test_data)
n_qubits = train_data.shape[1] # Number of qubits
qnode = setup_pennylane_circuit(n_qubits, 5)
n_params = 5 * n_qubits * 3 # Number of trainable parameters
print('Number of parameters involved: {}'.format(n_params))
Number of parameters involved: 60
[15]:
cost_func = partial(cost_function, qnode=qnode,
train_data=train_data, train_labels=train_labels)
problem = Problem(n_params=n_params, param_bounds=(- cp.pi, cp.pi), init_range=(- cp.pi, cp.pi), obj_function=cost_func, backend='gpu', vectorized=False)
[16]:
optimizer = GA(
selection=sel_tournament,
crossover=cx_uniform,
mutation=mut_gaussian,
cxpb=0.9,
mut_indpb=0.25
)
[18]:
res = optimizer.optimize(problem, pop_size=10, max_gen=20, seed=1, verbose=True)
res
Generations: 10%|███ | 2/20 [00:00<00:00, 19.65gen/s]
********** Execution #1 **********
gen nfev min max mean std
----- ------ -------- -------- -------- ---------
0 10 0.650329 0.947386 0.747862 0.0918746
1 10 0.64318 0.912444 0.72793 0.0802623
2 10 0.601074 0.72883 0.662113 0.0372224
3 10 0.601074 0.800428 0.677 0.0634095
4 10 0.601074 0.902105 0.721889 0.100713
Generations: 40%|████████████ | 8/20 [00:00<00:00, 20.03gen/s]
5 10 0.598125 0.839488 0.702297 0.0793839
6 10 0.598125 0.881257 0.72386 0.08676
7 10 0.481134 0.798423 0.666046 0.0983832
8 10 0.425562 0.76862 0.580563 0.0991216
9 10 0.425562 0.816829 0.635246 0.152609
Generations: 65%|██████████████████▊ | 13/20 [00:00<00:00, 19.97gen/s]
10 10 0.40962 0.843335 0.642727 0.152564
11 10 0.40962 0.927286 0.697986 0.14453
12 10 0.40962 0.851464 0.643269 0.125917
13 10 0.40962 0.727623 0.580227 0.113876
Generations: 80%|███████████████████████▏ | 16/20 [00:00<00:00, 20.02gen/s]
14 10 0.40962 0.831035 0.678999 0.11337
15 10 0.40962 0.731908 0.585875 0.11345
16 10 0.403068 0.87274 0.636615 0.157095
17 10 0.403068 0.883448 0.666935 0.130822
18 10 0.403068 0.916513 0.664277 0.139977
Generations: 100%|█████████████████████████████| 20/20 [00:00<00:00, 20.01gen/s]
19 10 0.403068 0.973204 0.666048 0.168796
20 10 0.403068 0.907873 0.733743 0.140554
[18]:
fun: array(0.40306812)
gen: 20
log: {'gen': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20], 'nfev': [10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10], 'min': [array(0.65032899), array(0.64318014), array(0.60107355), array(0.60107355), array(0.60107355), array(0.59812518), array(0.59812518), array(0.48113362), array(0.42556227), array(0.42556227), array(0.40962049), array(0.40962049), array(0.40962049), array(0.40962049), array(0.40962049), array(0.40962049), array(0.40306812), array(0.40306812), array(0.40306812), array(0.40306812), array(0.40306812)], 'max': [array(0.94738568), array(0.91244404), array(0.72883022), array(0.80042805), array(0.90210504), array(0.83948786), array(0.88125667), array(0.79842266), array(0.76862013), array(0.81682863), array(0.84333495), array(0.92728622), array(0.85146369), array(0.72762343), array(0.83103504), array(0.73190822), array(0.87274045), array(0.88344844), array(0.91651345), array(0.97320435), array(0.90787308)], 'mean': [array(0.74786231), array(0.7279299), array(0.66211314), array(0.67700046), array(0.72188874), array(0.70229746), array(0.72385966), array(0.66604589), array(0.58056319), array(0.63524576), array(0.64272742), array(0.69798579), array(0.64326899), array(0.58022692), array(0.67899866), array(0.58587547), array(0.63661526), array(0.66693506), array(0.66427675), array(0.66604819), array(0.7337426)], 'std': [array(0.09187462), array(0.08026233), array(0.03722244), array(0.06340954), array(0.10071281), array(0.07938394), array(0.08676), array(0.09838319), array(0.09912159), array(0.15260851), array(0.1525639), array(0.14452978), array(0.12591695), array(0.11387558), array(0.11337005), array(0.1134497), array(0.15709521), array(0.1308217), array(0.13997732), array(0.16879555), array(0.1405539)]}
nfev: 210
x: array([ 0.54125542, 3.14159274, -0.24208669, 2.68002074, -2.46419543,
2.3696741 , -2.97896107, 2.53024464, 1.41391799, 0.71072874,
-1.138851 , 2.7430523 , 1.45057536, -1.89663949, 1.19214558,
-0.61467061, -3.06813588, 0.60285057, -1.15169006, -3.14159274,
-2.63604459, -0.43330107, -2.51216369, 3.14159274, 1.36701213,
0.69040062, 3.14159274, 0.31957977, -2.23431185, -0.97491111,
1.45299636, 1.72479951, 2.18279218, -3.14159274, 1.67944417,
0.17446883, 3.14159274, 1.30357679, 3.14159274, 2.30240089,
0.35430314, -0.66196917, -1.19970214, -3.1256582 , 3.14159274,
-0.35936334, -1.77529513, 0.57313125, -2.31104951, -1.51527373,
0.2068915 , -0.86823637, -1.44865689, -3.14159274, 2.5004251 ,
3.14159274, -2.3795737 , -1.17744205, 0.99007205, 2.57084034])
[19]:
test_preds = [get_label(res.x, qnode, feats) for feats in test_data]
test_accuracy = accuracy_score(test_labels, test_preds)
print("Test accuracy", test_accuracy)
Test accuracy 0.9333333333333333